AI-driven BizTalk-migrering till Azure

Snabbare, säkrare BizTalk-migrering – AI-driven discovery med människan kvar vid ratten
AI-driven BizTalk-migrering handlar inte om att låta en språkmodell skriva om er kod. Den börjar mycket tidigare – i arbetet med att förstå vad som faktiskt finns i miljön, innan en enda rad flyttas till Azure. Det är där många migreringar fastnar, och det är där vi på Contica sätter in AI och ny teknik tillsammans med djup kunskap om integrationsplattformar i BizTalk och Azure och den kunskap som bara era egna experter sitter på. AI sätter tempot, men besluten fattas av människor. I den här artikeln visar vi hur vi tänker, varför ett naivt “kasta in allt i en språkmodell” inte håller, och hur vi byggt den inledande fasen av en migrering så att den blir snabb, förutsägbar och minimerar framtida risk för fel.

Varför stannar BizTalk-migreringar innan de ens börjar?
Många migrering från BizTalk till Azure fastnar inte i kodningen. De fastnar i förståelsen. Man kör i diket en bit in i projektet. En typisk BizTalk-miljö består av tiotals (ibland fler) orkestreringar, över hundra mappningar, pipelines, portar och hundratals scheman – addera ibland tusentals beroenden mellan dem. Att refaktorera koden är den enkla delen. Den svåra delen är att förstå hur plattformen faktiskt hänger ihop: varför varje mönster valdes, vad varje port och map gör, och inte minst vilken affärsprocess som integrationen stöttar.
Den kunskapen sitter sällan i dokumentationen. Den sitter i huvudet på de två eller tre personer (inte sällan en person) som har full koll på BizTalk-miljön som har jobbat med den i åratal. Att översätta BizTalk-artefakter direkt till Azure blir aldrig bra. Azure är en annan plattform med andra regler och sätt att göra saker på. Att brygga denna diskrepans i en Discovery är viktigt. Vad riskerar man om man inte har rätt metodik stöttad av rätt teknik? Resultatet blir veckor, ibland månader, av workshops och kunskapsöverföring där konsulter ni tagit in skickar stora fakturor innan en enda rad kod har flyttats. Den kostnaden landar hos kunden, innan något värde har levererats.
Vad menar vi med discovery – och varför är det inte “bara en analys”?
Vi kallar den inledande fasen för discovery. Och vi vet att den ibland landar fel, för den missförstås lätt som “bara en analys” – ett mellansteg man betalar för innan det riktiga arbetet börjar. Så är det inte. Det vi bygger i den här fasen är migreringskontext: det underlag som hela den efterföljande migreringen vilar på. Inte en rapport som hamnar i en pärm, utan den gemensamma, faktabaserade grund som gör att scope, validering, arkitektur och själva flytten kan göras på fast mark i stället för på antaganden.
Skillnaden är inte semantisk. En migrering som startar utan den här grunden bygger in fel tidigt – i Azure-fundamentet eller i arkitekturen – och de felen blir teknisk skuld som är dyr både i framtida Azure-spend och i förvaltning i åratal framåt. Discovery är det som gör att vi slipper den kostnaden av att halvvägs in upptäcka att projektet vilar på fel grund.
“Vi känner ju vår egen miljö – varför behövs det här?”
Det är en rimlig invändning, och svaret är viktigt: det här handlar inte om att lära er något om er egen miljö, och det ersätter inte er kunskap eller den dokumentation ni redan har. Ni vet hur er BizTalk fungerar. Poängen är en annan.
Det vi skapar är ett migreringskritiskt underlag som vi bygger upp tillsammans med er – ett underlag som är strukturerat så att vår expertis, er verksamhetskunskap och AI-agenterna i nästa steg kan arbeta mot exakt samma sanning. Er kunskap finns i huvuden och i samtal; den blir svår att agera på maskinellt och svår att överlämna mellan team. Det vi gör är att fånga den i en form som är fullständig, konsekvent och möjlig att resonera kring – för både människor och agenter. Ni får dokumentationen på köpet, men det är inte det som är värdet. Värdet är att vi tillsammans skapar grunden som gör migreringen beslutbar.
Varför fungerar inte “kasta in det i AI:n”?
Det självklara svaret 2026 är: klistra in orkestreringen, be om en migreringsplan, klart. Och det fungerar – i en demo. Problemet är inte att AI:n ljuger. Problemet är att den inte ser tillräckligt.
En språkmodells context window rymmer kanske ett par artefakter åt gången – en orkestrering och en mappning. Men en migreringsplan behöver hålla hela miljön i huvudet samtidigt: alla orkestreringar, alla mappningar, alla pipelines, portar, scheman och framför allt de tusentals beroendena mellan dem. När modellen bara ser två av hundratals artefakter svarar den “ser okomplicerat ut, låg risk, en sprint” – inte för att det är sant, utan för att den inte kan se det dolda orkestreringsmönstret som spränger projektet. Ett självsäkert svar grundat på 2 % av informationen är farligare än inget svar alls, eftersom det hamnar i en offert.
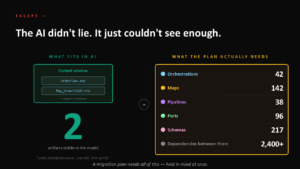
Men har ni tänkt på tokens?
Ja, det har vi. Och det är förmodligen den viktigaste frågan att ställa innan man bygger något AI-drivet på allvar.
Den naturliga reflexen när context window inte räcker är att lösa det med rå kraft: dela upp miljön i bitar, loopa över dem, kör agenter som läser allt. Men agenter som läser om allt, gör nya försök och sammanfattar om och om igen bränner token-budgeten i rasande takt – en månads budget kan vara slut på tre dagar. Och du får ändå inte det du behöver: chunking löser inte problemet, eftersom de uppdelade bitarna tappar relationerna mellan artefakterna – och det är just relationerna som en migreringsplan vilar på.
Här finns en frestande invändning: modellerna blir ju starkare för varje månad, och context window växer. Löser inte nästa modellgeneration det här åt oss? Vår erfarenhet säger nej. Kostnaden per token sjunker inte i samma takt som ambitionerna växer, och ett arbetssätt som bygger på att läsa om hela miljön vid varje körning skalar inte – det blir dyrare ju mer du använder det, och resultatet går aldrig att granska eller återskapa. Att lita på att en starkare modell ska rädda en ohållbar metod är inte en strategi, det är en räkning som skickas senare.
Därför har vi designat metoden tvärtom: den tunga förståelsen sker deterministiskt och utan tokens, och AI:n läggs på sist, på ett litet och destillerat underlag. Det gör kostnaden förutsägbar oavsett hur stor miljön är eller vilken modell vi kör. Så kan man arbeta i skarpa projekt. Att brute-forca en hel BizTalk-miljö genom en språkmodell kan man inte.

Hur använder vi AI i stället? Expert-kontext-mönstret
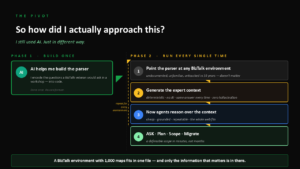
Lösningen är inte att sluta använda AI. Det är att använda det på ett annat sätt, i två tydligt åtskilda faser.
- Fas 1: bygg en gång. AI hjälper oss att bygga en parser. Vi kodar in de frågor som en BizTalk-veteran skulle ställa i en workshop – direkt i kod. Det görs en gång och återanvänds för alltid.
- Fas 2: kör varje gång. Vi riktar parsern mot vilken BizTalk-miljö som helst, oavsett om den är odokumenterad, obekant eller orörd i tio år. Parsern genererar AI-kontexten deterministiskt – utan AI i själva extraktionen, samma svar varje gång, noll hallucination. Först därefter låter vi agenter resonera över den färdiga kontexten. Då blir det billigt, grundat och repeterbart, och hela miljön ryms på en gång. En BizTalk-miljö med tusen mappningar får plats i en enda fil – och bara den information som faktiskt spelar roll finns i den.
Skiftet är alltså: AI används för att bygga verktyget, inte för att läsa miljön. Den deterministiska extraktionen kostar inga tokens och hallucinerar inte. Agenterna kommer in sist, när de står på ett pålitligt underlag.
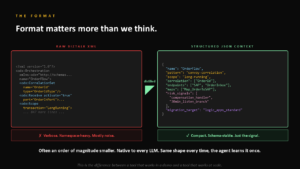
Varför är formatet avgörande?
En detalj som är lätt att underskatta: formatet på kontexten avgör om verktyget fungerar i en demo eller i skarp drift. Rå BizTalk-XML är mångordig, namespace-tung och till största delen brus. Destillerad till strukturerad JSON blir samma information ofta en storleksordning mindre – kompakt, schemastabil och med bara signalen kvar.
Det spelar roll av tre skäl. JSON är token-effektivt och får plats i vilket context window som helst. Det är native för varje LLM. Och det har samma form varje gång, så agenten lär sig strukturen en gång och kan sedan köra frågor mot den för flöden som talk, plan och scope. En orkestrering reduceras till sitt mönster (till exempel convoy-correlation), sitt scope, sina korrelationer, endpoints, mappningar och – viktigast – sina risksignaler som compensation handlers och långa listen branches.
Vad betyder kontexten – och var kommer människan in?
Här är en distinktion som är värd att vara tydlig med. Det parsern producerar är AI-kontext – den täta, maskinläsbara råvaran. Men det är inte samma sak som migreringskontext. Migreringskontext är vad AI-kontexten blir när vår metodik och era experter har tolkat den: råvaran plus omdöme, plus verksamhetens kunskap, plus en integrationsstrategi. Det första kan en maskin producera. Det andra kan den inte.
Och det är därför människan är central, inte ett tillägg. AI-kontexten är ett utkast, inte ett facit. Den följs alltid av en mänsklig validering av en av våra tekniker med djup BizTalk-kunskap, och därefter en gemensam genomgång tillsammans med era egna experter på er miljö. Vår tunga expertis är sällan värd något utan verksamhetens egen kunskap – det är ni som vet varför ett visst flöde ser ut som det gör och vilka beroenden som inte får röras. Det vi gör är att frigöra den kunskapen snabbare, och ge era experter ett underlag som gör att de kan ställa och besvara rätt frågor direkt.
Och här löses en skenbar motsättning upp. När vi säger att discovery går på minuter i stället för månader menar vi kartläggningen – det manuella arbetet med att förstå vad som finns, som förr åt veckor av workshops. Den mänskliga tiden försvinner inte. Den flyttas uppåt, till de beslut som faktiskt kräver omdöme: vilka delar som ska moderniseras, var riskerna ligger, hur strategin ska se ut. Vi tar bort den tråkiga väntan, inte den kloka diskussionen.
Från kontext till färdig migrering
När migreringskontexten väl finns på plats är destinationen ofta given: orkestreringar mot Logic Apps Standard, kodtung logik mot Azure Functions, HTTP-endpoints mot API Management, köer mot Service Bus, pub/sub mot Event Grid. Måltjänsterna finns redan – de behöver bara ren indata.
Det är här vår egen IP gör skillnad. Tillsammans med kontexten lägger vi våra beprövade templates och vår metodik för att sätta rätt grund i Azure från början – fundamentet som allt annat vilar på, från struktur och behörigheter till CI/CD, namnstandarder och säkerhet. Att få det rätt från start är skillnaden mellan en migrering som blir billig att förvalta och en som bygger in teknisk skuld redan dag ett. Och eftersom migreringskontexten är strukturerad för att agenter ska kunna resonera över den, kan vi koppla på AI även i själva genomförandet – med planering, scope och utförande på ett underlag som är tillförlitligt. Det är så vi genomför den faktiska migreringen betydligt snabbare än vad som var möjligt tidigare, utan att tumma på grunden.
En körning ger dessutom två utdata samtidigt. För teamet: levande dokumentation – markdown-rapporter per orkestrering, beroendegrafer, inventeringar av portar och scheman, ett riskregister med komplexitetspoäng, färdiga överlämningsunderlag. För agenterna: en tät, strukturerad JSON-kontext. Dokumentation som inte blir inaktuell, och kontext som inte hallucinerar – från en och samma källa.
Fungerar det bara för BizTalk?
Nej, och det är poängen. Mönstret är inte bundet till BizTalk. Det går att rikta mot vilket äldre, odokumenterat system som helst – MuleSoft, TIBCO, SAP PI/PO, WCF, mainframe-COBOL. Samma tre steg gäller: bygg parsern med hjälp av AI genom att koda in expertens frågor, extrahera kontexten deterministiskt, resonera över den med agenter. BizTalk i dag, SAP i morgon, COBOL dagen därpå. Mönstret reser.
Det är därför vi internt sammanfattar det så här: experterna är inte borta. Deras kunskap väntar bara på att kodas in.
Vill du veta mer?
Om du står inför en migrering från BizTalk till Azure och tror att AI borde kunna hjälpa er att komma i mål snabbare – då tycker vi att du borde höra av dig till oss. Vi tar en första dialog kring var du är och hur ni tänker. Vi kallar det Bring your problem. Efter det kan vi avgöra om det kan vara värt för er att starta en AI-Optimerad Discovery-fas med era experter i centrum.
Du kan läsa mer om vår approach till migrering från BizTalk till Azure här.
Dela detta inlägg

Fler inlägg att sätta tänderna i

Så blir en POC till ett beslutsunderlag du vågar lita på vid migrering från BizTalk till Azure

Ahmed Bayoumy på Integrate 2026 – BizTalk-migrering

BizTalk-migrering till Azure: så kortar AI tiden
